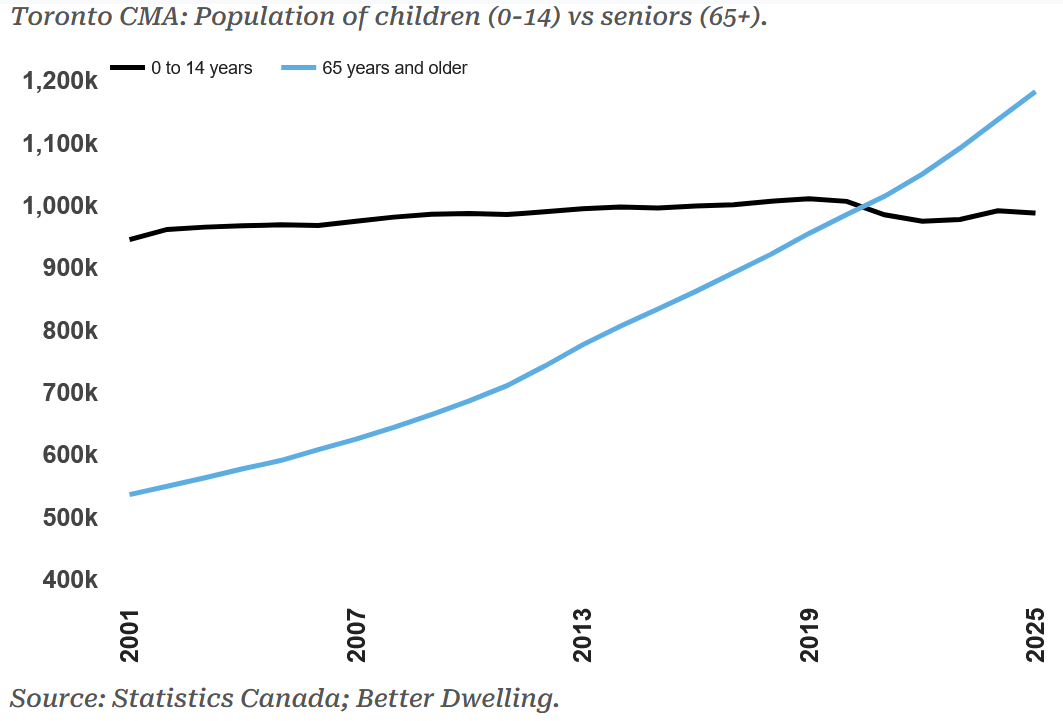
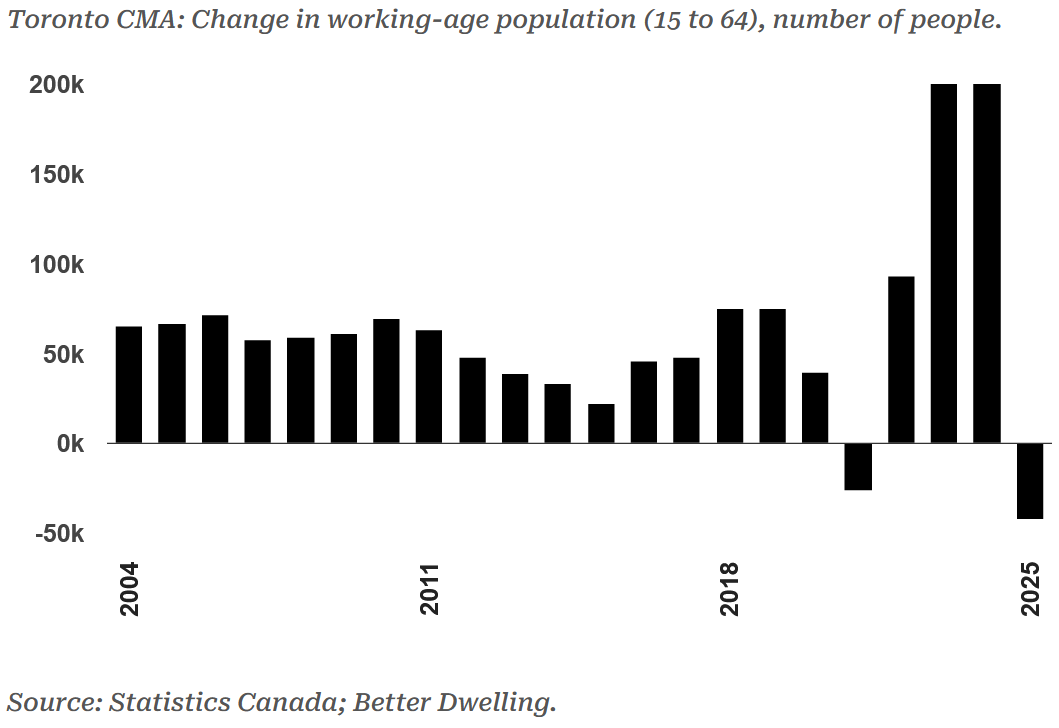
Checking in on Andy
Posted on July 14th, 2026 – Comments Off on Checking in on AndyAndy Byford isn’t exactly a household name so let me fill you in on his bona fides.
Andy was chief general manager, then CEO, of Toronto’s public transit system (TTC), for nearly six years (2011-2017). By 2014 he had his foot in the door of the New York’s Metropolitan Transit Authority (MTA) and immediately after his departure from the TTC he became president of a similar body in New York. In all three capacities he was to modernize the transit system.
Here’s Andy “Train Daddy” Byford:
What a smile.
I had some criticisms of his tenure during his time in Toronto and recall that his vision for the transit system led to a marked reduction in service just as he was heading out the door:
October 12, 2017
The following is a joint statement from TTC Chair Josh Colle and TTC CEO Andy Byford.News by Bombardier Transportation today that a promised delivery of a cumulative total of 70 streetcars by the end of this year has been revised to 65 is extremely disappointing and frustrating.
There should be 146 new streetcars in service today; instead there are just 45. This is completely unacceptable. The TTC is having to continue to use buses on streetcar routes to meet ridership demand.
The TTC is pursuing a $50 million legal claim against Bombardier for its ongoing failure to meet delivery targets and the TTC Board has directed staff to pursue other potential suppliers for future streetcar orders. In the meantime, the TTC is making every effort to keep its old streetcars on the road as long as it can, ensuring they are both reliable and safe.
There was also the fumbled Toronto-York Spadina Subway Extension, $150 million over budget and 2 years behind schedule at the time that Andy picked up and left. Under his watch there were also other budget problems, even as transit fares increased. And the fact that the subway refresh was completed successfully under his watch is not something he can take much credit for; he mostly just guided that inherited train into the station.
A year after relocating to New York, Andy unveiled his plan to improve the city’s bus routes. He left the position in 2020 and, 6 years later, little progress appears to have been made.
Leaving his New York job he almost immediately slid into a very similar role in London, England. He quit that position two years later. Unsurprisingly, Transport for London was left with budget holes and disgruntled workers. Similarly, Andy’s main accomplishment was to oversee the completion of a project someone else had started.
In 2023 he joined Amtrak as Vice President of High-Speed Rail Development Programs and last year Trump appointed him as a special advisor to the Amtrak Board of Directors. I expect a train wreck followed by a hasty exit.